IPC 통신 - MSA 전환으로 인해 발생하는 문제, 그리고 개선하기 위한 방안
모듈 분해로 인해 발생 가능한 문제들 (개발자 관점)
1. 요청에 대한 처리량(throughput)이 급격히 하락
- 각 서비스의 정확히 필요한 컴퓨팅 리소스 파악 어려워진다.
- 즉 필요한 컴퓨팅 자원의 최적화가 어려워 성능 하락의 가능성이 생긴다.
2. http, gRPC 프로토콜 상의 이슈로 디버깅이 어렵다.
- Connection Pool 관리
- Monolithic 환경에 비해 한정된 리소스로 JVM 최적화가 더 어려워진다.
- 추가로 http, gRPC 프로토콜에 디펜던시가 있는 지식이 필요하다.
- Connection Timeout, tcp-3handshake, gRPC code …
모듈 분해로 인해 발생 가능한 문제들 (운영/유지보수 관점)
1. 모니터링 방식의 고도화
- Monolithic 환경에 비해 많이 어려워진 디버깅과 트러블슈팅
- 서비스간 호출 상태
- Latency 증감 확인
- Call 증감 확인
- Async 방식에 대한 모니터링 (ex. Kafka)
- 다양한 Business Metrix
2. 로그 수집을 위한 별도의 인프라 필요 및 관리의 필요성 (ex. DevOps Team)
3. 수십, 수백개의 서비스에 대해 JVM / hardware 에 대해 정상적인지 지속적인 모니터링 필요
4. 개발되는 수많은 서비스로 인해 서비스간 호출이 적절한지 파악하기 어려움
MSA 전환 문제를 풀기위한 기술
1. 분해에 의해 생긴 1차적인 문제 해결
- 관리해야할 수많은 서버와 서비스(프로세스)를 배포 하고 관리하는 Container (docker)
- 그로인해 생긴 컨테이너를 관리하는 Container Ochestration (k8s)
- docker-compose 와 유사하지만 훨씬 더 복잡하고 다양한 기능을 지원한다.
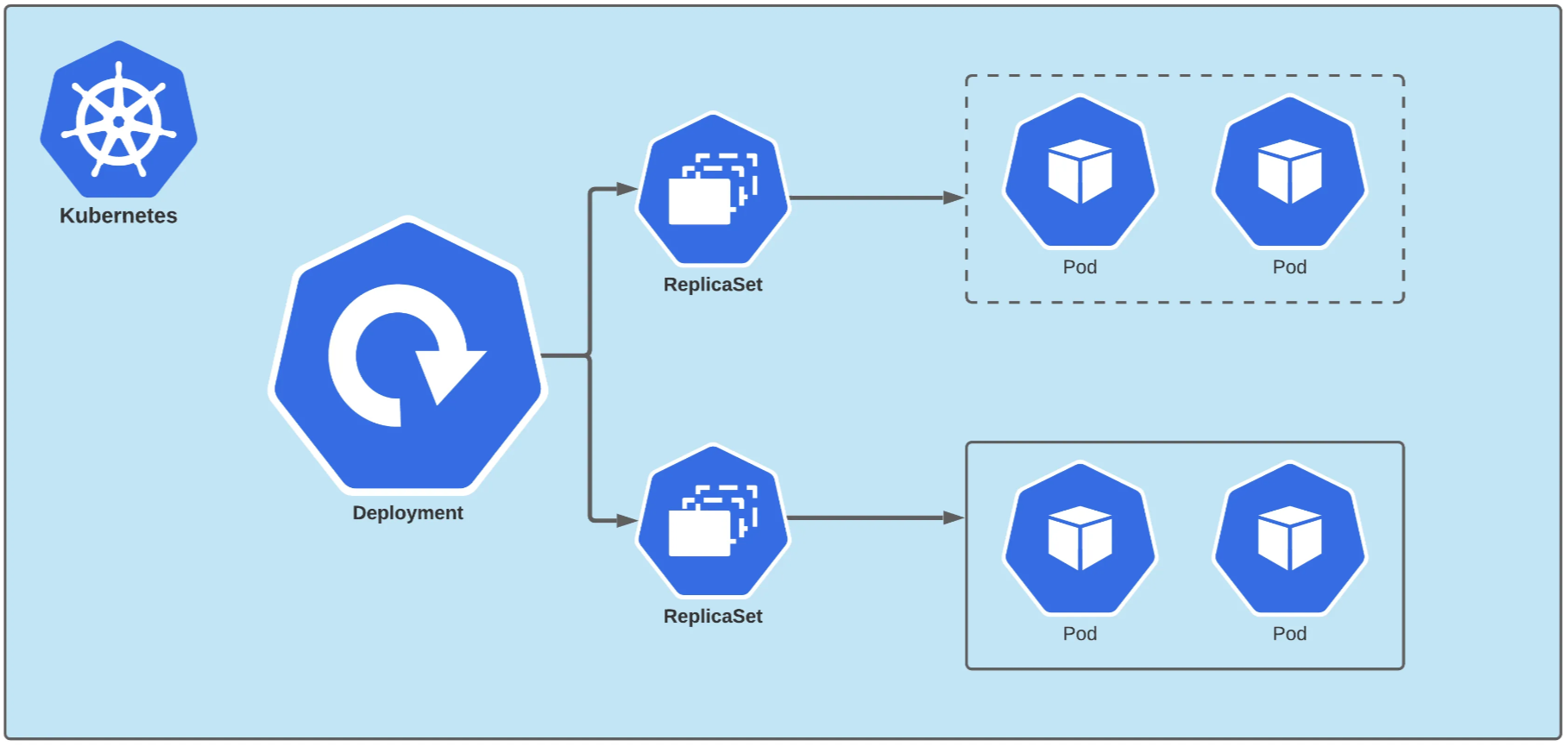
출처: https://yankeexe.medium.com/how-rolling-and-rollback-deployments-work-in-kubernetes-8db4c4dce599
2. 유지보수의 문제 해결
- 많은 hop 로 이한 요청 장애 파악하는 문제 -> Tracing
- 로그 수집을 위한 별도의 인프라 필요 -> Logging
- JVM / 하드웨어 모니터링 -> Metric
- 정상적인 서비스간의 호출을 하고 있는지에 대한 모니터링 -> Service-Mesh
MSA 환경에서의 적절한 모니터링
Logging, Metric, Alert, Tracing, Service-Mesh
- 특정 Metric 에 사전 정의 디어진 Alert 를 통해서 문제를 감지한다.
- 확인 필요한 상황 발생
- 어떤 Metric 에 대한 문제인지를 파악하고, 어떤 행동을 해야할 지 판단
- Metric 수치를 보고 판단을 잘못 했는지, 혹은 당장 이슈의 정도가 미미하다면 Alert 조건 수정
- Application 레벨의 문제라고 판단 될시에는, Log 를 확인
- 로그 확인으로 어려울시, 트랜잭션에 대한 Tracing 확인
- 라우팅, 트래픽 등의 문제라면 Service-Mesh 를 통해 현재 서비스간 트래픽 모니터링 상태 확인
- 같은 문제가 발생하지 않도록 회고
로깅 (Logging)
- 수많은 서버(IDC, Cloud) 내의, 서비스들의 로그들을 적절히 필터링 하여 누락 없이 로그 저장소까지 전송해야 한다.
- 수많은 로그들을 적절히 인덱싱 하여, 필요시 빠르게 다양한 조건으로 검색이 가능하야 한다.
EFK - Kibana, Fluentd, Elasticsearch

메트릭 / 얼럿 (Metric / Alert)
- 수많은 서버 (IDC, Cloud) 내의, 수많는 서비스 내 메트릭들을 안정적으로 수집하고, 시계열 방식으로 저장 해야한다.
- 시계열 DB: 시간의 흐름에 따라서 데이터를 조회할 수 있는 것에 최적화된 데이터베이스
- 원하는 복잡한 형태의 비즈니스 메트릭을 작성하고, 이를 기반으로 적절하게 Alert 조건을 설정할 수 있어야 한다.
Prometheus (대표적인 시계열 DB), Grafana (저장된 메트릭을 대쉬보드화 하여 보여주는 도구)

트레이싱 (Tracing)
- 하나의 소스(트랜잭션)에 대해서, 여러개의 서비스에서 어떤 과정들을 거쳐 수행되었는지 확인해야한다.
- 적절한 샘플링과 보기좋은 UI 들을 제공해야 한다.
Jaeger, Zipkin, Tempo
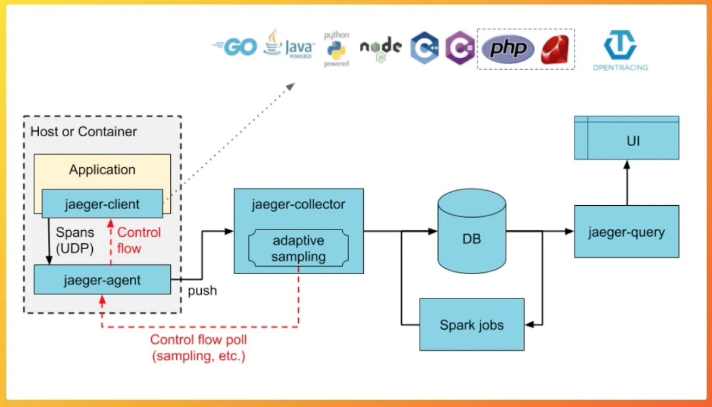
출처: [https://www.jaegertracing.io/]
Service-Mesh
- 어느 서비스가 어느 서비스를 호출하고 있는지, 어디로 트래픽이 어느정도로 발생하고 있는지 등을 모니터링 할 수 있어야 한다.
Istio, Kiali
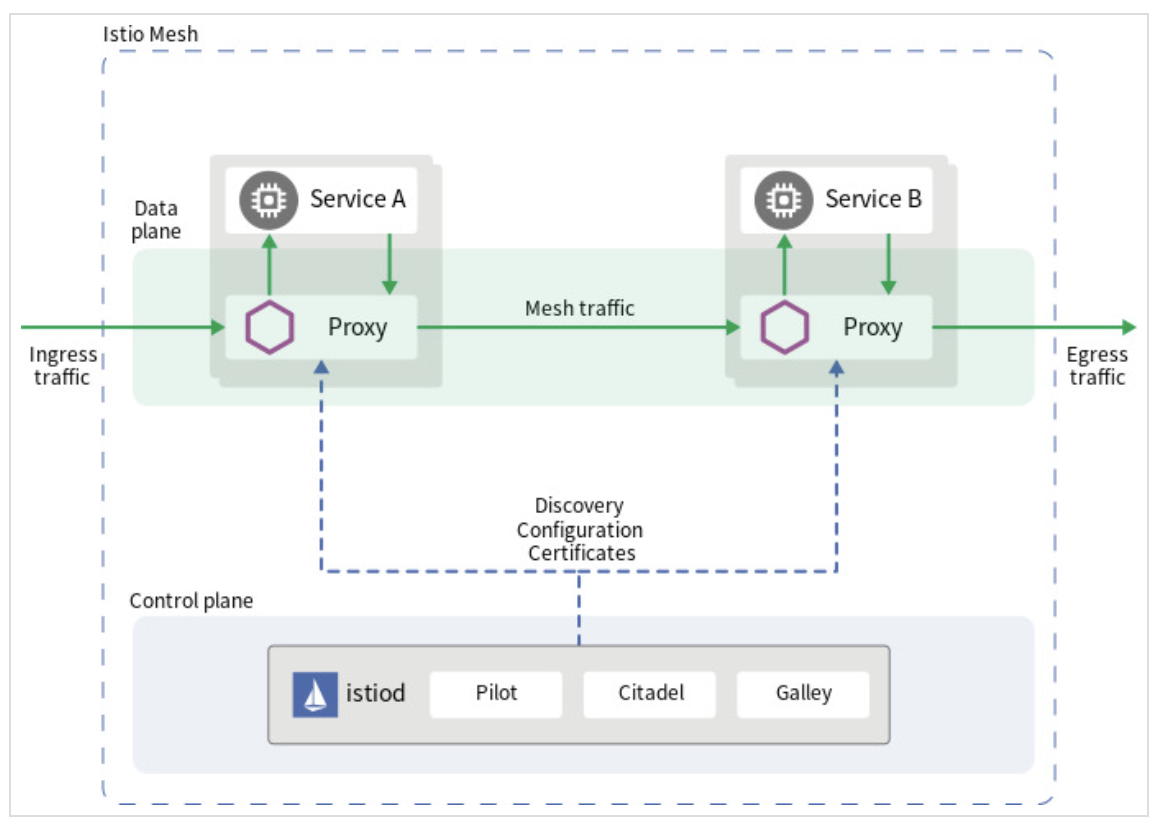
This post is licensed under CC BY 4.0 by the author.