카프카(Kafka) 에 대해 알아보자
카프카(Kafka) 란?
카프카(Kafka)는 링크드인(Linked-in) 에서 처음 개발되어 2011년 오픈소스화 된 솔루션이다. 실시간으로 스트리밍 데이터를 게시/ 구독/ 저장 및 처리할 수 있는 “분산형 데이터 스트리밍 플랫폼” 이다.
기존의 직접적인 (end-to-end) 연결 방식의 아키텍처는 데이터 연동의 복잡성이 높고 확장이 어려운 구조인 반면, kafka 를 사용하면 보내는 쪽에서는 kafka 로 메시지를 보내면 되고, 받는 쪽에서도 누가 그 메시지를 생성하고 보냈는지에 관계없이 단순하게 메시지 자체를 가져와서 처리할 수 있게 된다.
이처럼 “확장이 용이한 시스템”이라는 점과 함께 “클러스터링에 의한 고가용성” 이라는 특징, “낮은 지연(Latency)과 높은 처리량(Throughput)”으로 인해 kafka 를 사용하면 많은 데이터를 효과적으로 처리할 수 있어 빅데이터 처리 등에서 많이 사용되는 추세이다.
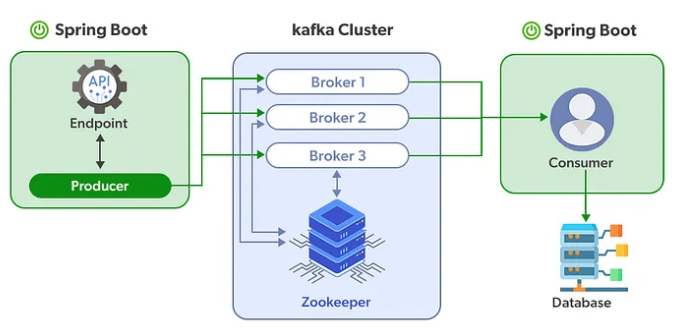
Kafka 공식 문서의 아키텍처(https://kafka.apache.org/090/documentation.html)를 참조해서 살펴보면 kafka 로 데이터를 보내는 Producer 와 kafka 에서 데이터를 가져오는 Consumer 가 있으며(producer 와 consumer는 각기 다른 프로세스에서 비동기로 동작), Kafka Cluster 를 중심으로 producer 와 consumer 가 데이터를 발행하고 구독하는 “Pub-sub (Publish-Subscribe)” 모델로 동작하고 있다는 것을 알 수 있다. 이러한 동작 방식으로 인해 kafka 는 분산 환경에 특화되어 있다는 특징도 가지고 있다.
Kafka Cluster (Zookeeper)
실제 서비스에서 사용되는 Kafka 는 고가용성을 위해 “여러 개의 Kafka 서버와 Zookeeper 로 구성된 클러스터 구조” 로 사용된다.
일반적으로 3개 이상의 kafka 서버(Broker)로 구성되며, 이러한 구조를 통해 broker에 저장된 메시지를 다른 broker에게 공유하고 하나의 브로커에 문제가 생겼을 때, 다른 브로커로 그 역할을 대체해서 시스템을 정상적으로 유지시키는 방식으로 동작한다.
각각의 Kafka Server를 Kafka Broker(또는 Bootstrap Server), n 개의 broker 중 1대는 리더의 역할을 수행
Zookeeper 는 분산 어플리케이션의 데이터 관리 기능을 가지고 있으며, 여러 개의 Broker 들을 컨트롤 해주는 역할을 수행하기 때문에 zookeeper 없이 kafka 가 동작할 수 없다.
Topic 과 Partition
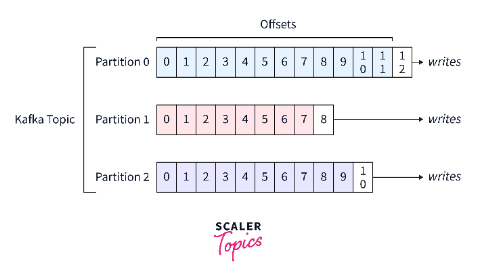
“Topic” 은 데이터가 들어갈 수 있는 공간을 이야기하며, 여러 개의 토픽이 생성될 수 있다.
즉, topic 은 Kafka Cluster 에서 데이터를 관리할 때 기준이 되는 요소가 된다. 또한 각각의 topic 은 이름을 가지는데, 목적에 따라 무슨 데이터를 담는지 명시하면 추후 유지보수 시 편리하게 관리될 수 있다. (topic은 파일 시스템의 폴더나 데이터베이스의 테이블과 유사한 성질을 가지고 있다)
각각의 topic은 1개 이상의 “Partition” 으로 구성되어 있다. 파티션은 토픽 안에서 데이터를 분산 처리하는 단위로 볼 수 있으며, 첫 번째 파티션은 0번부터 시작된다. 하나의 파티션은 Queue와 같이 파티션 끝에서부터 데이터가 쌓이게 되고, Consumer 는 가장 오래된 순으로 데이터를 가져가게되 된다.
Kafka 는 Consumer 가 데이터를 가져가도 파티션에 있는 데이터가 삭제되지 않는다는 특징이 있다. 때문에 동일 데이터에 대해 여러번 처리를 할 수 있으며, 이는 Kafka 를 사용하는 중요한 이유 중 하나이다.
프로듀서(Producer) 와 컨슈머(Consumer)
Kafka의 프로듀서(Producer)와 컨슈머(Consumer)는 분산 메시지 시스템에서 데이터를 생성하고 처리하는 데 사용되는 핵심 구성 요소이다. 이들은 대용량의 데이터를 효율적으로 처리하고 저장할 수 있는 강력한 기능을 제공한다. (Producer 와 Consumer 는 동일한 Topic 명으로 연계되어 동작)
1. Producer
프로듀서는 데이터를 생성하고 Kafka 클러스터로 전송하는 역할을 담당한다. 데이터의 소스는 다양할 수 있으며, Web Application, Sensor, Log File 등 다양한 소스에서 발생하는 데이터를 생성할 수 있다.
프로듀서는 Kafka 클러스터의 주소를 알고 있어야 하는데, 이 주소는 보통 프로커의 주소로 구성되며 보통은 프로커의 호스트 이름과 포트 번호로 구성된다.
프로듀서는 생성된 데이터를 특정 토픽에 전송한다. 토픽은 데이터의 카테고리를 나타내며, 여러 개의 파티션으로 나뉘어져 있고, 프로듀서는 전송할 데이터와 토픽의 이름을 명시하여 Kafka 클러스터로 데이터를 보냅니다.
프로듀서는 메시지를 전송할 때 데이터의 키와 값의 쌍으로 전송할 수 있다. 이렇게 전송된 데이터는 Kafka 클러스터의 특정 토픽에 저장이 되고, 키는 메시지를 파티셔닝하는 데 사용되며, 동일한 키를 가진 메시지는 동일한 파티션에 저장됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
@Component
public class LoggingProducer {
private final KafkaProducer<String, String> kafkaProducer;
private final String topic;
// 각 Service 에 따라 서로 다른 환경변수 값
public LoggingProducer(
@Value("${kafka.clusters.bootstrapservers}") String bootstrapServers,
@Value("${logging.topic}") String topic
) {
// Producer Initialization
Properties properties = new Properties();
// kafka:29092
properties.put("bootstrap.servers", bootstrapServers);
/**
* kafka cluster 에 모든 데이터를 key:value 쌍으로 produce 한다.
* @serialize 란?
* - produce 를 함에 있어서 각각의 key 와 value 를 어느 data 로써 판별을 하고 serialize 할 것 인가?
* - produce 란 작업은 결국 각각의 Service 에서 Kafka Cluster 라는 External System 으로 데이터가 옮겨 가는것이기 때문에
* Kafka 가 해당 데이터를 "어떻게 간주 해서 kafka cluster 의 특정 broker 안에 Produce 된 데이터를 가지고 있을 것인가?" 를 정의하는 것이다.
*/
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
this.kafkaProducer = new KafkaProducer<>(properties);
this.topic = topic;
}
public void sendMessage(String key, String value) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
kafkaProducer.send(record, (metadata, exception) -> {
if (exception == null) {
// 성공
// System.out.println("Message sent successfully. Offset: " + metadata.offset());
} else {
// 실패
exception.printStackTrace();
// System.err.println("Failed to send message: " + exception.getMessage());
}
});
}
}
프로듀서는 Kafka의 분산 아키텍처를 활용하여 데이터를 안정적으로 전송합니다. Kafka 클러스터의 여러 브로커에 프로듀서를 분산하여 데이터를 전송하므로, 대용량의 데이터를 효율적으로 처리할 수 있습니다.
2. Consumer
컨슈머는 Kafka 클러스터에서 데이터를 읽어들이고 처리하는 주체이다. 특정 토픽을 구독하여 메시지를 소비하는데, 이때 여러 개의 컨슈머가 동일한 토픽을 구독할 수 있다. 각 컨슈머는 토픽의 파티션을 할당받아 메시지를 읽어들이는데, 이를 통해 데이터를 병렬로 처리할 수 있다.
컨슈머는 읽어들인 데이터를 처리하여 필요한 작업을 수행한다. 예를 들어, 데이터를 DB에 저장하거나, 실시간 분석을 수행할 수 있다. 이렇게 처리된 데이터는 비즈니스 응용 프로그램에서 활용되어 다양한 용도로 활용될 수 있습니다.
또한 컨슈머는 각 파티션에서 읽은 마지막 오프셋(offset)을 관리한다. 이를 통해 컨슈머는 중복된 데이터를 방지하고, 데이터의 일관성을 유지할 수 있다. 또한 오프셋을 기반으로 컨슈머는 이전에 처리한 데이터 이후부터 다시 시작할 수 있다.
그리고 컨슈머 그룹은 Kafka 클러스터의 브로커 갯수 변경이나 컨슈머의 추가/제거와 같은 상황에서 자동으로 파티션 할당을 조정하는 리밸런싱 수행을 통해 시스템의 확장성과 안정성을 유지할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
@Component
public class LoggingConsumer {
private final KafkaConsumer<String, String> consumer;
public LoggingConsumer(
@Value("${kafka.clusters.bootstrapservers}") String bootstrapServers,
@Value("${logging.topic}") String topic
) {
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
// Consumer Group
props.put("group.id", "my-group");
/**
* Producer 와 Consumer 간에 serialize - deserialize 합이 맞아야 원할하게 데이터를 저장가능하다.
*/
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topic));
Thread consumerThread = new Thread(() -> {
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
// print to Stdout
System.out.println("Received message: " + record.value());
}
}
} finally {
consumer.close();
}
});
consumerThread.start();
}
}
이렇게 컨슈머는 Kafka의 분산 아키텍처를 활용하여 데이터를 안정적으로 처리하고, 대용량의 데이터를 효율적으로 처리할 수 있다.